
专知编辑

ChatGPT和GPT-4等大型语言模型(LLM)在NLP领域取得了重大进展。然而,它们记忆、表示和利用常识性知识的能力一直是LLM众所周知的痛点。目前尚不清楚:(1) GPTs能否有效地回答常识问题? (2) GPTs在常识方面有知识吗?(3) GPTs是否意识到回答特定问题所需的基本常识知识? (4) GPTs能否有效地利用常识来回答问题?为了评估上述常识问题,我们进行了一系列实验来评估ChatGPT的常识能力,实验结果表明:(1) GPTs可以在常识任务中取得良好的QA准确性,同时在某些类型的知识上仍有困难。(2) ChatGPT知识丰富,能够利用知识提示准确地生成大部分常识知识。(3) ChatGPT虽然知识丰富,但却是一个缺乏经验的常识问题求解器,无法精确识别回答某一特定问题所需的常识知识,即ChatGPT并不精确知道回答一个问题需要哪些常识知识。上述发现提出了需要研究在LLM中利用常识知识的更好机制,如指令遵循、更好的常识指导等。
https://arxiv.org/abs/2303.164211 引言
常识知识是人类认知的一个基本方面,它包括我们对世界的直觉理解和我们对世界的推理能力。它包括关于典型日常生活的空间、物理、社会、时间和心理方面的知识,以及对社会规范、信仰和价值观的理解,以及预测和解释人类行为的能力(Liu and Singh, 2004)。常识知识对于构建能够理解和生成类人语言的NLP系统至关重要。尽管常识知识对许多任务都很重要,但在机器中获取和表示常识知识一直是NLP中的一个长期挑战(Li et al., 2021;Zhang et al., 2022),因为常识往往是隐式的,并依赖于上下文(Gordon和Van Durme, 2013;Shwartz和Choi, 2020)。近年来,人们对解决NLP模型的常识问题以及实现更类似人类的语言生成和理解的兴趣越来越大(Bauer等人,2018;Wang等人,2020;江等,2021;刘等人,2021,2022)。
最近,大型语言模型(LLM)如GPT-3 (Brown et al., 2020)、ChatGPT和GPT-4在广泛的NLP能力方面取得了显著的成功,包括推理、上下文理解和思维链推理(Wei et al.,2022)。这些能力表明,大型语言模型具有一定程度的常识知识(West et al.,2022)。然而,常识问题往往被认为是大型语言模型的一个主要限制(Zhou等人,2020;Bhargava和Ng, 2022)。随着这些模型变得越来越强大,目前仍不清楚它们在多大程度上能够理解和推理常识知识边缘。这就提出了几个关键问题:
(1) GPTs能否有效地回答常识性问题?
(2) GPTs在常识方面知识渊博吗?
(3) GPTs是否意识到回答特定问题所需的基本常识知识?
(4) GPTs能否有效地利用常识来回答问题?
回答这些问题对于理解LLM的能力和局限性,以及开发更好的方法来评估和提高它们在常识任务上的表现至关重要。
为了评估模型回答常识问题的能力,使用了11个常识问答数据集,涵盖了8个不同的常识领域,包括物理、社会、时间和数值推理等。首先,我们要求模型回答这些问题,并评估其回答的准确性。为了评估大型语言模型是否理解了回答这些问题所需的常识知识,我们要求模型描述必要的知识,并评估描述是否准确。为了评估大型语言模型是否能够回忆和描述回答问题所需的知识,我们要求模型是否知道必要的知识,并评估回答是否正确和相关。最后,为了评估模型是否可以利用常识知识进行推理,我们将之前实验中产生的知识作为上下文,并要求模型再次回答问题。我们将它们的表现与使用黄金知识进行比较,并评估它们的推理过程是否可以有效地利用已识别的知识。
我们的实验为大型语言模型的常识问题提供了见解:(1)GPTs可以在常识任务中实现良好的QA准确性,而它们在某些类型的知识方面仍然很困难。(2) ChatGPT知识丰富,可以使用知识提示准确地生成大部分常识知识。(3) ChatGPT是缺乏经验的常识问题求解者,无法准确识别解决特定问题所需的常识知识。此外,ChatGPT不能有效地利用上下文中的常识知识来回答特定问题。本文的主要贡献在于:
我们通过进行实验详细研究了大型语言模型的常识能力来回答4个关键问题。
我们设计了一系列实验来评估ChatGPT记忆、表示和利用常识知识的能力,包括回答常识问题,识别和生成必要的知识,以及在其推理过程中利用常识知识。
通过确定ChatGPT在常识知识和推理能力方面的优势和劣势,我们为开发更高级的语言模型提供了见解,这些模型可以有效地利用和推理常识知识。
2 什么是常识
常识是“人类经验的很大一部分,包括关于典型日常生活的空间、物理、社会、时间和心理方面的知识。(Liu and Singh, 2004;布拉赫曼和莱维斯克,2022年)。这种类型的知识通常被认为是理所当然的,通常是通过在特定文化中多年的经验和社会化获得的。为了帮助读者更好地理解这一概念,我们总结了几类主要的常识:一般常识:这类常识指的是被广泛分享并被大多数人认为是正确的知识,例如太阳从东方升起,从西方落下。物理常识:这类常识涉及关于物理世界的知识,比如物体掉落时会落到地面,水会往下坡流。
社会常识:这类常识涉及社会规范、风俗习惯和实践方面的知识,比如提出请求时说“请”和“谢谢”是礼貌的。
科学常识:这类常识涉及基本的科学概念和原理,例如地心引力将地球上的所有物体拉向地球中心。
事件常识:这类常识涉及到事件的先后顺序以及它们之间的因果关系的知识,比如杯子被打翻了,里面的液体就会洒出来。
数值常识:这种类型的常识涉及有关数字的知识,例如人类有两只手和十个手指。
原型常识:这类常识包括关于概念的典型或原型例子的知识,例如燕子是一种鸟,鸟有翅膀。时间常识:这类常识涉及时间知识,例如出国旅行比散步需要更长的时间。
3 GPTs能有效地回答常识问题吗?
在这一节中,我们评估了LLM回答常识问题的表现。具体来说,我们使用了11个常识QA数据集,涵盖了8个常识领域,包括通用、物理、社会、科学、事件、数值、原型和时间。这11个数据集是common – monsenseQA (Talmor等人,2019)、OpenBookQA (Mihaylov等人,2018)、WSC (Levesque等人,2012)、PIQA (Bisk等人,2020)、Social IQA (Sap等人,2019)、ARC (Clark等人,2018)、QASC (Khot等人,2020)、HellaSWAG (Zellers等人,2019)、NumerSense (Lin等人,2020)、ProtoQA (Boratko等人,2020)和MC-TACO (Zhou等人,2019)。数据集及其域,每个数据集都有一个示例,如表1所示。
我们从每个常识QA数据集的开发集中抽样了100个问题用于评估,除了ProtoQA,它的开发集中只有52个问题。我们使用GPT-3 (davinci)、GPT- 3.5 (text-davinci-003)和ChatGPT作为用于评估的大型语言模型。对于GPT-3,我们使用4-shot in-context学习。对于GPT-3.5和ChatGPT,我们使用零样本推理,并为不同的数据集设计提示模板。
结果如表2所示。从结果可以看出:
GPTs能够准确回答常识性问题。我们在11个常识QA数据集上评估了不同LLM的性能。表2的结果显示,GPT-3.5和ChatGPT都可以在大多数数据集上取得良好的性能。表现最好的数据集是ARC和ProtoQA, ChatGPT在这两个数据集上的准确率分别达到了94%和94.2%。这些结果表明,像GPT-3.5和ChatGPT这样的大型语言模型对于常识性问题是有效的问题解决器,可以在不同类型的常识性问题中提供准确的答案。
GPTs利用常识知识的能力可以通过指令调优和人类对齐来提高。我们比较了三种大型语言的性能表2中的models、GPT-3、GPT-3.5和ChatGPT。从结果中我们可以看到,GPT-3.5和Chat- GPT相比GPT-3取得了显著的提升。这些结果表明,仅靠预训练不足以学习利用知识。通过结合指令和对齐调整技术(欧阳等人,2022),模型可以更好地利用和推理常识知识。
总的来说,ChatGPT在大多数领域取得了比GPT-3.5更高的准确率,证明了RLHF技术在增强知识利用能力方面的有效性。然而,GPT-3.5在某些数据集上的表现略优于ChatGPT,包括CommonsenseQA和社交IQA。这是因为ChatGPT往往比较谨慎,在信息不足的情况下拒绝给出答案,导致出现“根据给出的信息,不可能确定……”这凸显了在信息不充分的模型中,如何平衡谨慎和准确性的问题,还需要进一步研究。要实现这一点,需要模型理解回答问题所需的知识,并意识到模型是否拥有该知识。
虽然GPTs在大多数常识知识领域表现良好,但在某些类型的知识方面仍存在困难。表2中的实验表明,大型语言模型在社交、事件和时间常识QA(社交IQA、HellaSWAG和MC- TACO数据集)上滞后。ChatGPT在这些数据集上的表现低于70%。这表明llm在社会、事件和时间常识知识上仍然存在缺陷。我们认为这是因为这些类型的常识知识需要对人类行为和社会互动有更深入的理解,而它们在文本语料库中很少出现。这表明,当前的LLM需要在这些常识领域上进行改进,这需要模型超越表面的语义理解,学习人类行为。
4. GPTs是否意识到回答问题的常识知识?
在第3节中,我们发现GPTs在常识性QA数据集上表现良好。这引起了我们的探索,GPTs是经验丰富的专家,他们知道需要什么知识,并可以利用这些知识进行问答,还是他们是缺乏经验的问题解决者,依赖于记忆大量涵盖问题的信息。
为了回答这个问题,我们从每个常识QA数据集中抽样了20个问题,并询问Chat- GPT“回答这个问题需要哪些知识?”对于有≥10个错误回答问题的数据集,我们抽样10个正确回答问题和10个错误回答问题,否则,我们采取所有错误回答的问题,抽样更多正确回答的问题,以填补这20个问题。
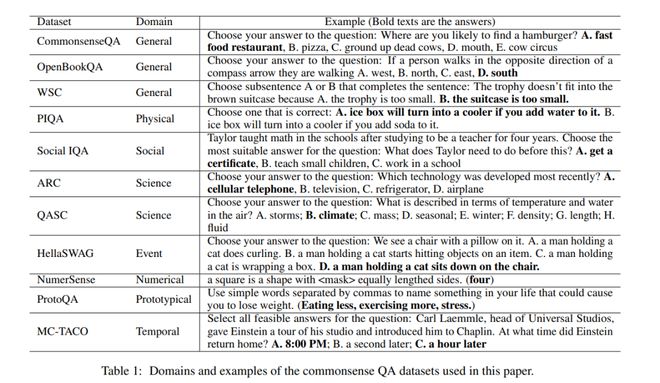
我们手动评估每个生成的回答的准确率和召回率,并使用F1分数作为衡量标准。例如,表3展示了ChatGPT的回答,描述了回答问题所需的知识。从ChatGPT的回应中,我们将知识1和知识3标记为回答问题有用,而知识2被过度泛化,知识4和知识5不是必需的。然后我们根据这2条知识判断问题是否可回答,并进一步在人工评价中额外写2条必要知识,知识a和知识b,这样,这个回答的精确率为2/5,召回率为2/4,F1分数为44.44%。
结果如表4所示,

ChatGPT是一个没有经验的问题解决者,它很难精确地识别回答特定问题所需的常识知识。我们手动评估ChatGPT生成的必要知识,结果如表4所示。结果显示,在大多数常识性QA数据集上,总体F1分数在40%到75%之间。这些结果表明,ChatGPT是一个经验不足的问题解决者,无法准确识别回答特定常识问题所需的知识。
具体而言,该模型在科学领域表现相对较好,在ARC和QASC上分别取得了74.57%和76.13%的F1值。然而,该模型在社交领域和时间领域(即社交IQA和MC-TACO)上表现最低。F1分数的这种差异很可能是因为科学常识知识在文本语料库中比社会和时间知识更普遍。例如,教科书经常讨论“气候由温度和湿度描述”等科学概念,但很少提及“学生不喜欢参加大考”等社会规范,或“吃一顿饭不需要几个月”等时间知识。这表明,像ChatGPT这样的大型语言模型在社会和时间领域仍然存在局限性。因此,开发更有效的训练策略来注入这些常识知识领域是很重要的。
GPTs无法有效区分回答特定问题的相关和不相关常识知识,通常会生成噪声率较高的知识。我们在表4中评估了生成的必要知识的精确率和召回率。所有数据集的平均召回率为84.42%,平均精确率为55.88%。这表明,虽然模型可以识别出大多数问题的常识知识,但它很难准确识别出哪些知识对于回答特定的常识问题是必不可少的。该模型通常生成的知识是不相关的或过度泛化的。例如,表3中的知识2是过度泛化的,因为问题本身是“如何制作户外枕头”,而知识4和5考虑到两种选择之间的差异,就显得不相关了。我们认为这是因为模型依赖的是关键词和主题匹配,而不是对问题内部的逻辑关系的充分理解。这进一步证明了GPTs仍然是缺乏经验的问题解决者。因此,llm需要增强对手头任务的自我意识,并将关键信息与无关背景信息区分开来。例如,他们需要能够判断一个问题的哪些部分对决策是必要的,比如表3中的“吹进锡罐/垃圾袋”,哪些部分是无关的。
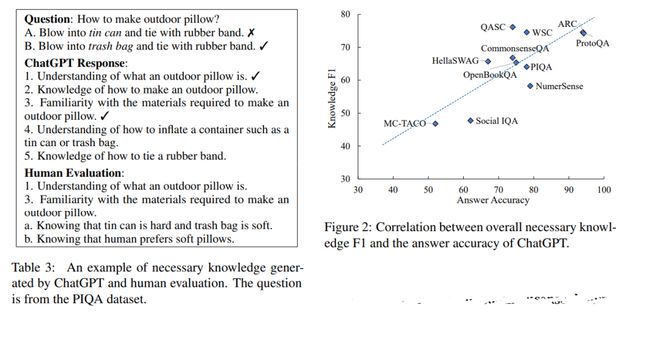
通过增强GPTs的知识意识(knowledge-awareness),即引导模型识别特定问题所需的知识,可以显著提高GPTs的常识能力。在图2中,我们绘制并分析了生成的必要知识的总体F1分数与答案之间的相关性ChatGPT的准确率。结果显示准确率和知识F1有很强的相关性,皮尔逊系数为0.77。此外,表4显示,正确回答问题的知识F1得分明显高于错误回答问题的知识F1得分。这些发现表明,准确识别必要的知识对于正确回答常识问题至关重要。因此,增强模型对必要知识的自我意识,有可能提高其在包括常识QA在内的下游任务上的性能。
5 . GPTs了解常识吗?
本节回答了这个问题:大型语言模型在多大程度上具有常识知识?为了回答这个问题,类似于Shwartz et al.(2020),我们根据第3节中生成的必要知识手动构建知识查询提示。例如,如表5所示,基于表3中的知识1,我们将问题写成“你对什么是户外枕头有了解吗?”我们将这些提示输入到ChatGPT中,并手动标注ChatGPT生成的每一个知识描述是否正确。

表5展示了一个知识查询问题的示例和生成的知识描述。第一个描述说“向垃圾袋吹气,用橡皮筋绑起来,可能会产生类似垫子的表面,但作为户外枕头,不太可能持久或舒适”,但在现实中,这是一种典型的做法。所以,这个描述被贴上了不正确的标签。
结果如表6所示。从结果可以看出:
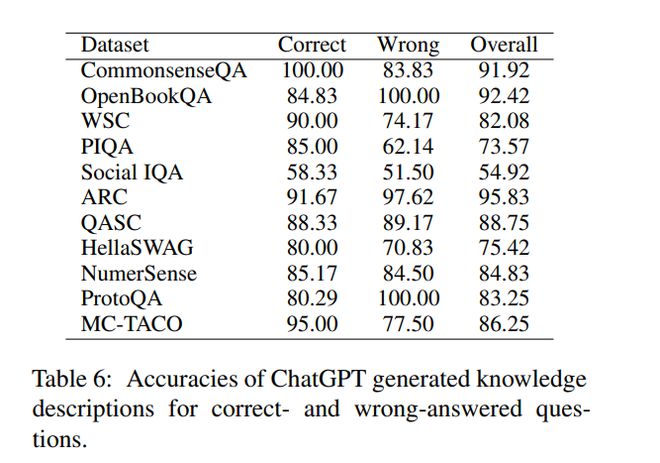
GPTs知识渊博,包含了准确回答问题所需的大部分常识知识。通过提出知识-查询问题和手动评估ChatGPT的响应,我们评估了ChatGPT中必要知识的准确性。表6的结果显示,ChatGPT生成的知识描述在大多数常识性QA数据集上都能达到70%以上的准确率,达到82.66%的平均准确率。这表明,在给定知识查询问题的情况下,ChatGPT可以生成准确的常识知识描述。这表明llm可以作为常识知识库,并为下游任务提供常识。然而,在社会领域的准确率较低,为54.92%。我们认为,这是因为社会常识,如“接受帮助的人,而不是给予帮助的人,应该说谢谢”,在文本中并不常见。这就突出了开发具体指导的重要性,可以指导ChatGPT获取社会常识知识。
GPT包含误导和过度泛化的常识知识。为了评估CommonsenseQA数据集上知识描述的相关性和信息量,我们进行了人工评估。结果显示,26.25%的描述包含不相关和误导性的信息,15.00%的描述过度泛化,未能提供回答问题所需的具体知识。例如,表5中的描述提到了“探索专门用于制作户外枕头的其他方法或材料”,这对于回答问题是没有帮助和误导性的。我们认为这是因为大型语言模型的训练数据中存在噪声和冗余信息,而损害对准确判断信息相关性的能力。这些发现强调了ChatGPT需要生成具有相关性和信息量的知识描述,以确保生成的结果对回答问题具有实用价值。
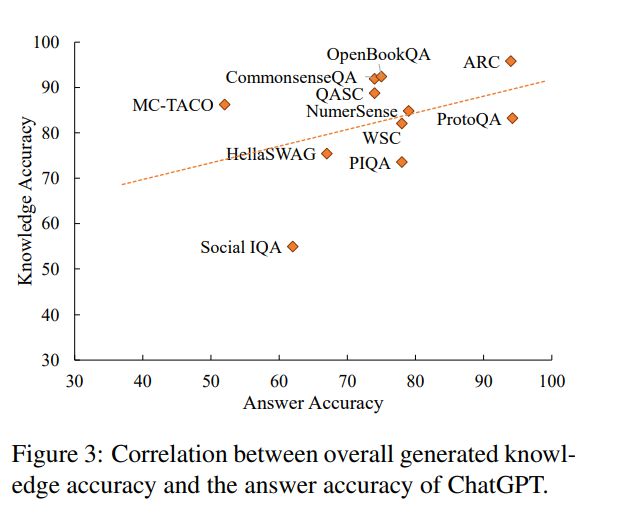
在LLM中,了解和利用常识知识之间存在差距。为了探索生成的知识描述的准确性和答案准确性之间的关系,我们进行了相关性分析,并在图3中绘制了结果。我们的结果显示,两个准确率之间存在微弱的相关性,皮尔逊系数为0.40。值得注意的是,虽然在社交IQA和MC-TACO数据集上的答案准确率都很低,但它们之间的知识描述准确率存在显著差异:社交IQA的准确率很低(54.92%),但MC-TACO的准确率很高(86.25%)。表6进一步显示,与第4节的结果相比,正确回答和错误回答的问题在描述准确率上的差异相对较小。这表明,好的知识描述并不一定能转化为正确的答案。我们认为这是因为回答常识性问题不仅需要知识,还需要在信息不足的条件下进行推理和推理等其他能力。
6. GPTs可以有效地利用上下文中的常识进行推理吗?
本节回答了一个问题:大型语言模型能否利用上下文中的常识知识进行推理和回答问题?为了回答这个问题,在回答了第4节中的知识查询问题后,我们要求模型再次回答常识问题,并评估在描述必要的知识后答案是否会发生变化。表7展示了一个先前不正确的答案在生成知识描述后仍然保持不变的例子。
结果如表8所示。从结果可以看出:
如果我们只将生成的常识添加到问题上下文中,ChatGPT无法有效利用这些常识。我们对生成知识描述前后答案变化的分析表明,在大多数数据集上,使用生成的常识后并没有明显和一致的准确性提升
既有从错误到正确的变化,也有从正确到错误的变化,还有相当大比例的未改变的答案,如表7所示的例子。在社交IQA数据集的情况下,知识生成的准确性较低,导致更多的正确答案被修改为错误。这说明ChatGPT无法有效利用自身生成的知识描述来回答问题,知识生成的准确性对回答结果有巨大影响。我们认为这是因为模型已经拥有了生成的知识,因此添加冗余知识是没有用的。
ChatGPT在常识QA方面的性能提升即使使用黄金知识也不显著。我们为common – monsenseQA数据集使用了两个人工标注的常识解释数据集CoS-E (Rajani et al.,2019)和ECQA (Aggarwal et al., 2021)作为黄金知识作为上下文,并要求ChatGPT生成答案。我们发现,给出CoS-E解释的只有4个错误→正确的答案,给出ECQA解释的只有8个错误→正确的答案,而有一个正确→错误的答案。这表明ChatGPT并不能回答所有的问题即使给出真实知识的解释,也能正确回答问题。我们认为这是因为大型语言模型缺乏使用知识进行复杂常识推理的能力,例如否定。例如,这里有一个需要否定推理的问题:“如果篮球上有一个洞,但它没有失去它的一般形状,那么关于篮球,有什么是不正确的?A.被刺破的,B.在美国流行的,C.充满空气的,D.消失了的,E.圆形的”。对这个问题的CoS-E解释是:“任何有洞的物体都不能留住空气。”,但ChatGPT仍然预测了错误的答案A,并解释道:“如果篮球上有一个洞,它就被刺穿了,空气就会从中逸出。”这些结果表明,大型语言模型需要进一步的指导和改进,以更好地利用和推理上下文中的常识性知识。
7 结论和讨论
在本文中,我们调研了大型语言模型的常识能力,发现ChatGPT是一个有知识但没有经验的问题解决者:(1) 虽然GPTs可以在常识QA中取得很好的准确性,但他们仍然在某些类型的知识上挣扎,包括社会和时间常识。(2) ChatGPT在常识方面知识渊博,可以使用知识提示准确地生成大部分常识知识。(3) ChatGPT是一个缺乏经验的常识问题求解者。它很难准确地识别给定问题的潜在常识知识,并且经常生成噪声率很高的知识。此外,ChatGPT不能有效地利用上下文中的常识知识来回答常识问题。
上述发现为未来的工作提出了几个有希望的方向:
(1) 虽然目前的GPTs知识丰富,但他们仍然没有经验解决问题。因此,研究在LLM中利用常识知识的更好机制至关重要,如指令调优、更好的常识引导推理等。
(2) LLM中仍然缺少几种类型的常识知识,如社会和时间常识。因此,为这些知识类型设计知识注入方法至关重要。此外,重要的是设计轻量级的常识更新方法,以保持知识的最新。
(3) 由于ChatGPT和GPT-4不会公布它们的全部细节,比如训练数据、超参数和检查点,评估一个“人工通用智能”模型是非常不同的,因此设计和构建覆盖范围更广的基准至关重要,设计评估方法能够对大型语言模型提供更全面和更公正的评估。
更多解读请看:https://t.zsxq.com/0c85za4kh
另外这里会保存我收集的各种关于AIGC的资源和资料,包括AI绘画-midjourney,ChatGPT, GPT-4,百度-文心一言的各种资料。会保持持续更新,欢迎大家自行拿取。



