


每一代GPT模型的参数量都爆炸式增长,堪称“越大越好”。2019年2月发布的GPT-2参数量为15亿,而2020年5月的GPT-3,参数量达到了1750亿。
还是有很多读者对于ChatGPT充满期待(幻想?梦想),今天给大家分享技术层面的拆解,读完之后是否是会理性一点呢?enjoy~
文末推荐几篇直接采访ChatGPT创始人视角的文章,共赏enjoy~
作者:陈巍博士,曾担任华为系自然语言处理(NLP)企业的首席科学家
去年12月1日,OpenAI推出人工智能聊天原型ChatGPT,再次赚足眼球,为AI界引发了类似AIGC让艺术家失业的大讨论。
ChatGPT 是一种专注于对话生成的语言模型。它能够根据用户的文本输入,产生相应的智能回答。这个回答可以是简短的词语,也可以是长篇大论。其中GPT是Generative Pre-trained Transformer(生成型预训练变换模型)的缩写。通过学习大量现成文本和对话集合(例如Wiki),ChatGPT能够像人类那样即时对话,流畅的回答各种问题。(当然回答速度比人还是慢一些)无论是英文还是其他语言(例如中文、韩语等),从回答历史问题,到写故事,甚至是撰写商业计划书和行业分析,“几乎”无所不能。甚至有程序员贴出了ChatGPT进行程序修改的对话。
ChatGPT和AIGC的联合使用
ChatGPT也可以与其他AIGC模型联合使用,获得更加炫酷实用的功能。例如上面通过对话生成客厅设计图。这极大加强了AI应用与客户对话的能力,使我们看到了AI大规模落地的曙光。
一、ChatGPT的传承与特点

▌1.1 OpenAI家族
我们首先了解下OpenAI是哪路大神。OpenAI总部位于旧金山,由特斯拉的马斯克、Sam Altman及其他投资者在2015年共同创立,目标是开发造福全人类的AI技术。而马斯克则在2018年时因公司发展方向分歧而离开。此前,OpenAI 因推出 GPT系列自然语言处理模型而闻名。从2018年起,OpenAI就开始发布生成式预训练语言模型GPT(Generative Pre-trained Transformer),可用于生成文章、代码、机器翻译、问答等各类内容。每一代GPT模型的参数量都爆炸式增长,堪称“越大越好”。2019年2月发布的GPT-2参数量为15亿,而2020年5月的GPT-3,参数量达到了1750亿。
GPT家族主要模型对比
▌1.2 ChatGPT的主要特点
ChatGPT 是基于GPT-3.5(Generative Pre-trained Transformer 3.5)架构开发的对话AI模型,是InstructGPT 的兄弟模型。ChatGPT很可能是OpenAI 在GPT-4 正式推出之前的演练,或用于收集大量对话数据。
ChatGPT的主要特点
OpenAI使用 RLHF(Reinforcement Learning from Human Feedbac,人类反馈强化学习) 技术对 ChatGPT 进行了训练,且加入了更多人工监督进行微调。此外,ChatGPT 还具有以下特征:1)可以主动承认自身错误。若用户指出其错误,模型会听取意见并优化答案。2)ChatGPT 可以质疑不正确的问题。例如被询问 “哥伦布 2015 年来到美国的情景” 的问题时,机器人会说明哥伦布不属于这一时代并调整输出结果。3)ChatGPT 可以承认自身的无知,承认对专业技术的不了解。4)支持连续多轮对话。与大家在生活中用到的各类智能音箱和“人工智障“不同,ChatGPT在对话过程中会记忆先前使用者的对话讯息,即上下文理解,以回答某些假设性的问题。ChatGPT可实现连续对话,极大的提升了对话交互模式下的用户体验。对于准确翻译来说(尤其是中文与人名音译),ChatGPT离完美还有一段距离,不过在文字流畅度以及辨别特定人名来说,与其他网络翻译工具相近。由于 ChatGPT是一个大型语言模型,目前还并不具备网络搜索功能,因此它只能基于2021年所拥有的数据集进行回答。例如它不知道2022年世界杯的情况,也不会像苹果的Siri那样回答今天天气如何、或帮你搜索信息。如果ChatGPT能上网自己寻找学习语料和搜索知识,估计又会有更大的突破。即便学习的知识有限,ChatGPT 还是能回答脑洞大开的人类的许多奇葩问题。为了避免ChatGPT染上恶习, ChatGPT 通过算法屏蔽,减少有害和欺骗性的训练输入。查询通过适度 API 进行过滤,并驳回潜在的种族主义或性别歧视提示。
二、ChatGPT/GPT的原理
▌2.1 NLP
NLP/NLU领域已知局限包括对重复文本、对高度专业的主题的误解,以及对上下文短语的误解。对于人类或AI,通常需接受多年的训练才能正常对话。NLP类模型不仅要理解单词的含义,还要理解如何造句和给出上下文有意义的回答,甚至使用合适的俚语和专业词汇。
▌2.2 GPT v.s. BERT
与BERT模型类似,ChatGPT或GPT-3.5都是根据输入语句,根据语言/语料概率来自动生成回答的每一个字(词语)。从数学或从机器学习的角度来看,语言模型是对词语序列的概率相关性分布的建模,即利用已经说过的语句(语句可以视为数学中的向量)作为输入条件,预测下一个时刻不同语句甚至语言集合出现的概率分布。ChatGPT 使用来自人类反馈的强化学习进行训练,这种方法通过人类干预来增强机器学习以获得更好的效果。在训练过程中,人类训练者扮演着用户和人工智能助手的角色,并通过近端策略优化算法进行微调。由于ChatGPT更强的性能和海量参数,它包含了更多的主题的数据,能够处理更多小众主题。ChatGPT现在可以进一步处理回答问题、撰写文章、文本摘要、语言翻译和生成计算机代码等任务。 BERT与GPT的技术架构(图中En为输入的每个字,Tn为输出回答的每个字)
BERT与GPT的技术架构(图中En为输入的每个字,Tn为输出回答的每个字)
三、ChatGPT的技术架构
▌3.1 GPT家族的演进
说到ChatGPT,就不得不提到GPT家族。ChatGPT之前有几个知名的兄弟,包括GPT-1、GPT-2和GPT-3。这几个兄弟一个比一个个头大,ChatGPT与GPT-3更为相近。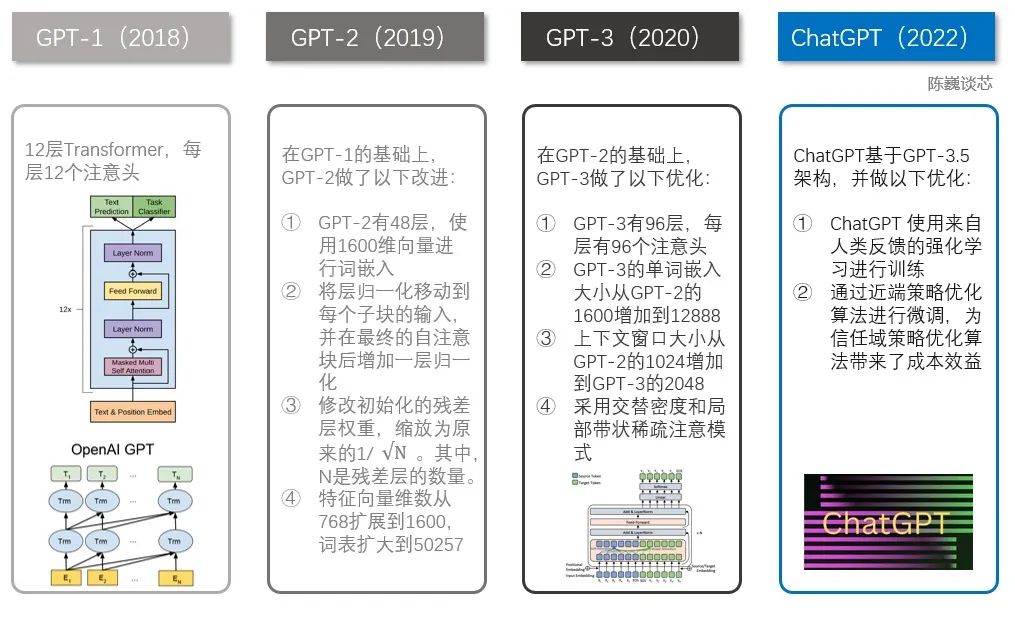
ChatGPT与GPT 1-3的技术对比
GPT家族与BERT模型都是知名的NLP模型,都基于Transformer技术。GPT-1只有12个Transformer层,而到了GPT-3,则增加到96层。▌3.2 人类反馈强化学习
InstructGPT/GPT3.5(ChatGPT的前身)与GPT-3的主要区别在于,新加入了被称为RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)。这一训练范式增强了人类对模型输出结果的调节,并且对结果进行了更具理解性的排序。在InstructGPT中,以下是“goodness of sentences”的评价标准。真实性:是虚假信息还是误导性信息?无害性:它是否对人或环境造成身体或精神上的伤害?有用性:它是否解决了用户的任务?▌3.3 TAMER框架
这里不得不提到TAMER(Training an Agent Manually via Evaluative Reinforcement,评估式强化人工训练代理)这个框架。该框架将人类标记者引入到Agents的学习循环中,可以通过人类向Agents提供奖励反馈(即指导Agents进行训练),从而快速达到训练任务目标。引入人类标记者的主要目的是加快训练速度。尽管强化学习技术在很多领域有突出表现,但是仍然存在着许多不足,例如训练收敛速度慢,训练成本高等特点。特别是现实世界中,许多任务的探索成本或数据获取成本很高。如何加快训练效率,是如今强化学习任务待解决的重要问题之一。而TAMER则可以将人类标记者的知识,以奖励信反馈的形式训练Agent,加快其快速收敛。TAMER不需要标记者具有专业知识或编程技术,语料成本更低。通过TAMER+RL(强化学习),借助人类标记者的反馈,能够增强从马尔可夫决策过程 (MDP) 奖励进行强化学习 (RL) 的过程。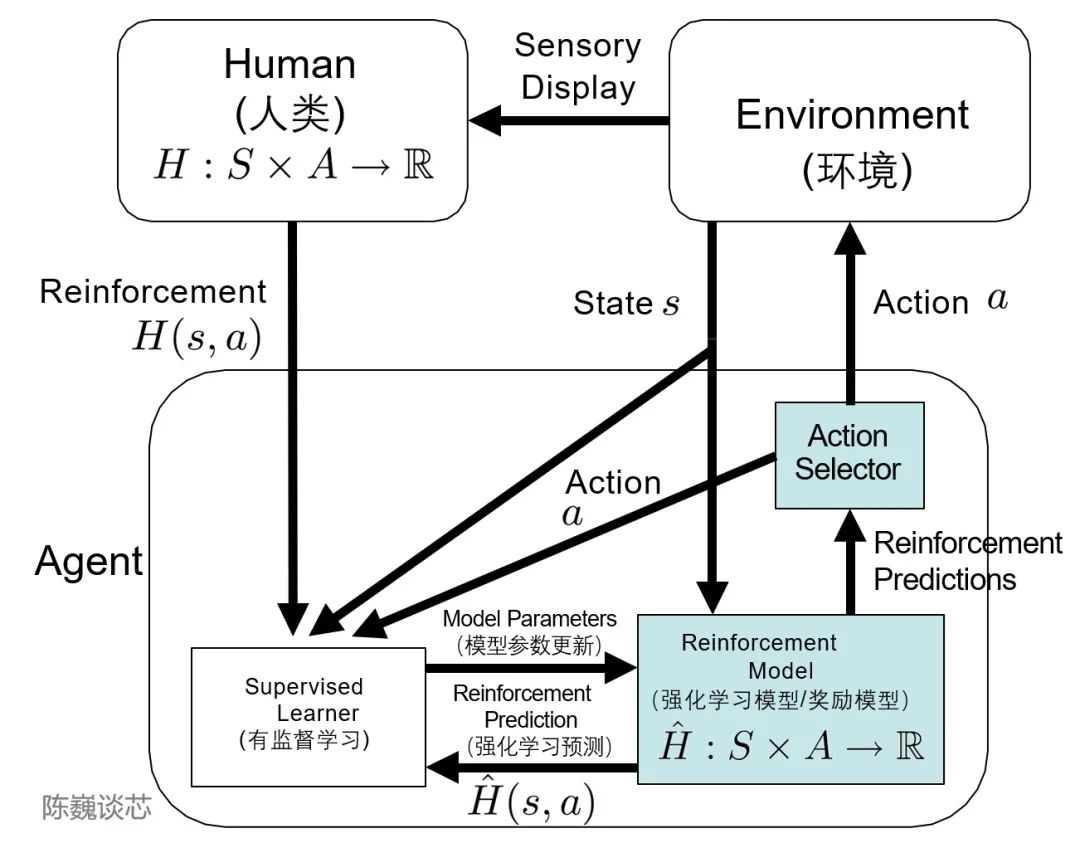
▌3.4 ChatGPT的训练
ChatGPT的训练过程分为以下三个阶段:第一阶段:训练监督策略模型GPT 3.5本身很难理解人类不同类型指令中蕴含的不同意图,也很难判断生成内容是否是高质量的结果。为了让GPT 3.5初步具备理解指令的意图,首先会在数据集中随机抽取问题,由人类标注人员,给出高质量答案,然后用这些人工标注好的数据来微调 GPT-3.5模型(获得SFT模型, Supervised Fine-Tuning)。此时的SFT模型在遵循指令/对话方面已经优于 GPT-3,但不一定符合人类偏好。
如果我们不断重复第二和第三阶段,通过迭代,会训练出更高质量的ChatGPT模型。
四、ChatGPT的局限
只要用户输入问题,ChatGPT 就能给予回答,是否意味着我们不用再拿关键词去喂 Google或百度,就能立即获得想要的答案呢?
尽管ChatGPT表现出出色的上下文对话能力甚至编程能力,完成了大众对人机对话机器人(ChatBot)从“人工智障”到“有趣”的印象改观,我们也要看到,ChatGPT技术仍然有一些局限性,还在不断的进步。1)ChatGPT在其未经大量语料训练的领域缺乏“人类常识”和引申能力,甚至会一本正经的“胡说八道”。ChatGPT在很多领域可以“创造答案”,但当用户寻求正确答案时,ChatGPT也有可能给出有误导的回答。例如让ChatGPT做一道小学应用题,尽管它可以写出一长串计算过程,但最后答案却是错误的。
那我们是该相信ChatGPT的结果还是不相信呢? fill=%23FFFFFF%3E%3Crect x=249 y=126 width=1 height=1%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
五、ChatGPT的未来改进方向
▌5.1 减少人类反馈的RLAIF
2020年底,OpenAI前研究副总裁Dario Amodei带着10名员工创办了一个人工智能公司Anthropic。Anthropic 的创始团队成员,大多为 OpenAI 的早期及核心员工,参与过OpenAI的GPT-3、多模态神经元、人类偏好的强化学习等。2022年12月,Anthropic再次发表论文《Constitutional AI: Harmlessness from AI Feedback》介绍人工智能模型Claude。(arxiv.org/pdf/2212.0807)
▌5.2 补足数理短板
ChatGPT虽然对话能力强,但是在数理计算对话中容易出现一本正经胡说八道的情况。计算机学家Stephen Wolfram 为这一问题提出了解决方案。Stephen Wolfram 创造了的 Wolfram 语言和计算知识搜索引擎 Wolfram | Alpha,其后台通过Mathematica实现。
▌5.3 ChatGPT的小型化
虽然ChatGPT很强大,但其模型大小和使用成本也让很多人望而却步。有三类模型压缩(model compression)可以降低模型的大小和成本。第一种方法是量化(quantization),即降低单个权重的数值表示的精度。比如Tansformer从FP32降到INT8对其精度影响不大。第二种模型压缩方法是剪枝(pruning),即删除网络元素,包括从单个权重(非结构化剪枝)到更高粒度的组件如权重矩阵的通道。这种方法在视觉和较小规模的语言模型中有效。第三种模型压缩方法是稀疏化。例如奥地利科学技术研究所 (ISTA)提出的SparseGPT (arxiv.org/pdf/2301.0077)可以将 GPT 系列模型单次剪枝到 50% 的稀疏性,而无需任何重新训练。对 GPT-175B 模型,只需要使用单个 GPU 在几个小时内就能实现这种剪枝。
SparseGPT 压缩流程
六、ChatGPT的产业未来与投资机会
▌6.1 AIGC
说到ChaGPT不得不提AIGC。AIGC即利用人工智能技术来生成内容。与此前Web1.0、Web2.0时代的UGC(用户生产内容)和PGC(专业生产内容)相比,代表人工智能构思内容的AIGC,是新一轮内容生产方式变革,而且AIGC内容在Web3.0时代也将出现指数级增长。ChatGPT 模型的出现对于文字/语音模态的 AIGC 应用具有重要意义,会对AI产业上下游产生重大影响。▌6.2 受益场景
从下游相关受益应用来看,包括但不限于无代码编程、小说生成、对话类搜索引擎、语音陪伴、语音工作助手、对话虚拟人、人工智能客服、机器翻译、芯片设计等。从上游增加需求来看,包括算力芯片、数据标注、自然语言处理(NLP)等。
大模型呈爆发态势(更多的参数/更大的算力芯片需求)
随着算法技术和算力技术的不断进步,ChatGPT也会进一步走向更先进功能更强的版本,在越来越多的领域进行应用,为人类生成更多更美好的对话和内容。最后,作者问存算一体技术在ChatGPT领域的地位(作者本人目前在重点推进存算一体芯片的产品落地),ChatGPT想了想,大胆的预言存算一体技术将在ChatGPT芯片中占据主导地位。(深得我心)
参考文献:
ChatGPT: Optimizing Language Models for Dialogue ChatGPT: Optimizing Language Models for Dialogue
GPT论文:Language Models are Few-Shot Learners Language Models are Few-Shot Learners
InstructGPT论文:Training language models to follow instructions with human feedback Training language models to follow instructions with human feedback
huggingface解读RHLF算法:Illustrating Reinforcement Learning from Human Feedback (RLHF) Illustrating Reinforcement Learning from Human Feedback (RLHF)
RHLF算法论文:Augmenting Reinforcement Learning with Human Feedback cs.utexas.edu/~ai-lab/p
TAMER框架论文:Interactively Shaping Agents via Human Reinforcement cs.utexas.edu/~bradknox
PPO算法:Proximal Policy Optimization Algorithms Proximal Policy Optimization Algorithms
原文链接:https://zhuanlan.zhihu.com/p/590655677来源:知乎,作者:陈巍, 由全球投融圈综合整理,转载请注明来源
免责声明:本公众平台发布的内容(包括文字、图片、影音等素材)部分来源于网络,转载内容不代表本平台观点,如涉及版权争议需要交涉,请直接联系原作者。如有侵犯您的权益或版权请及时告知我们,本平台客服查核属实后,将第一时间删除消息,不承担任何法律责任。热烈欢迎朋友们关注、转发、收藏本微信平台消息。
招生进行时朱朱老师 课程推荐:国内高校最高端“企业家学习平台”,报名咨询:13701386927朱老师(同微信)
相关推荐
招生中|(2021级)公司治理与金融硕士班 第39期招生简章
朱老师 13701386927(同微信)



