
前言
2023 Spring,美国UT Austin建筑学院的Daniel Koehler教授开设了基于ChatGPT和MidJourney的硕士Advanced Studio,算是全球最先一批基于新AI技术开设的studio。我有幸作为助教参与了课程的整体过程。目前Studio进度刚到三分之一,然而出现的成绩已经非常可观。
时值AIGC成为时代最热点,私以为将此次studio中期内容分享介绍给国内的建筑朋友,算是有意义的事情。也借此机会,贡献一些我对最近发生的事情的认知。
由于篇幅太长,文章划分为上中下三篇。此篇为Ai+建筑科普篇。中篇讨论AI和建筑学在数据层面更深刻的联系及历史交集,下篇谈论Studio详细内容。
当下——文字和图像的爆发
目前正在发生什么,实在是千头万绪。
ChatGPT、MidJourney、AIGC等已经成为了建筑师群里谈论最火热的文字,也已彻底改变了我的工作生活习惯。在写今天的文章之前,我会习惯问问ChatGPT它觉得自己和建筑学是什么关系。AAE的LOGO设计也是从MidJourney数百方案中选出来的。国内在建筑设计一线实践的同事们,都已将MidJourney用在日常设计之中。例如今天看见TS学长分享的一个工作流:用chatGPT描述想要生成的建筑,然后将生成的文本输入到MidJourney中得到方案比选。

这些年来,理论丧失了指导的作用,反而不断由技术来重塑理论和价值。虽然全世界高校一直为了探索新的建筑可能性写了无数文章,业界协会为了建筑学的发展捧起无数明星。但是到头来,最近十多年真正对建筑行业的设计质量和工作流产生革命性影响的,一是SketchUp,二是Enscape,三是现在的MidJourney。
去年——图像生成的新生
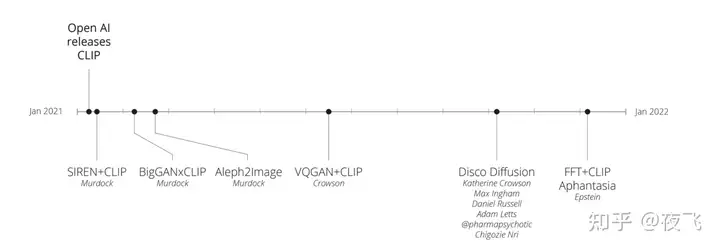
MidJourney并不是第一个文字到图像的软件。文本到图像的研究始于2015年前后。技术转折发生在2022 年。去年,OpenAI 的DALL-E 2、Google Brain 的Imagen和 StabilityAI 的Stable Diffusion等最先进模型的生成图片开始接近真实照片和人类绘画的质量。这些模型被认为将彻底改变艺术创作领域。其中唯一开源的是Stable Diffusion。
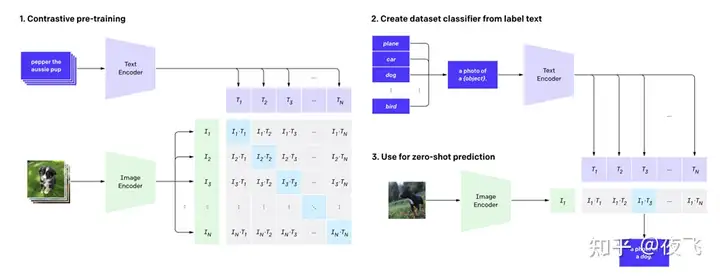
尽管生成式AI模型名字五花八门,但是其中最核心的部分都是由OpenAI开发的开源预训练模型Contrastive Language-Image Pretraining (CLIP),发布于2021年1月。经过4亿张带有标签的图片训练后,CLIP 具有天花板级别的图像内容识别能力,可以计算图像和文本的语义向量的相似程度,将图像用文本描述出来。CLIP具有“零样本学习”(ZSL,Zero-shot Learning)能力,一种强大的模型泛化能力。意思是训练集虽然只有猫和狗,它却能擅长检测浣熊这个训练集不存在的生物。
实际上,在AI领域,只要实现了语义测量,内容生成模型将会水到渠成。
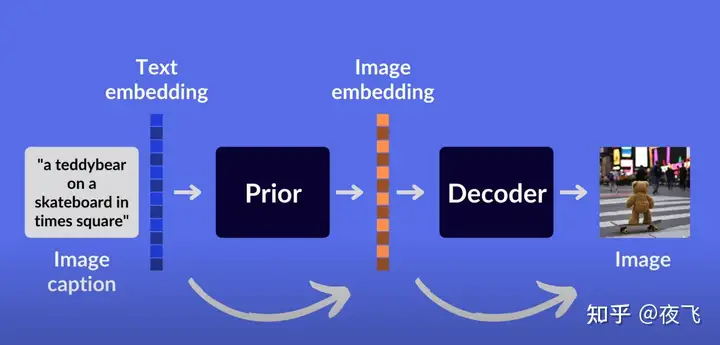
CLIP输入图像输出文本。OpenAI 很快就将CLIP模型结构的输入输出颠倒,所谓“unCLIP”,在发布CLIP的同时就发布了DALL-E,一个具有 12B 参数的大型图像生成模型(不过与早一年发布的语言模型GPT-3的175B相比还是更小一些)。2021年1月,DALL-E成为了首批引起公众广泛关注的文本到图像模型。它的结构逻辑是:文本——文本嵌入——图片嵌入——图片——使用卷积网络将图像从 64×64放大到 1024×1024。2022年4月DALL-E2发布,更小(3.5B)却更强。遗憾的是,DALL-E并不开源。
2022年3月,MidJourney内测发布,4月发布第二版,很显然,MidJourney的诞生也离不开CLIP的开源。尽管MidJourney本身并不开源。7月份MidJourney第三版进入公测。OpenAI于2022年8月开源了Stable Difussion模型,这意味着研究人员可以用自己的电脑GPU来调整模型,生成大量图片而无需调用API。在DALL-E 2、Stable Diffusion等模型中,CLIP 编码器直接集成到 AI 模型中,它们的嵌入由使用的扩散模型处理。
生成式方法中除了对抗神经网络外,值得一提的是diffusion model扩散模型。它的原理是“迭代降噪”。在最近两年,diffusion model取代对抗神经网络成了图像生成领域最热门的方法。它和CLIP一结合,就是目前主流的“CLIP-Guided Diffusion”模式。
MidJourney尚在内测阶段就已在先锋建筑事务所和高校得到火爆反应,在6月底的上海DigitalFUTURES上,尽管ZAHA依然保存了元宇宙为主题的工作营,然后在工作营过程中,ZHACODE导师们已经在分享基于MidJourney的方案生成。高校的反应还要更快,在五月份,Matias del Campo, Daniel Koehler等人已经开始发布基于此的设计作品。



基于CLIP的生成式模型也在这半年已经有很多研究成果。他们的研究框架可以简述为:1、事先有了某种rule-based的3D模型生成方法。2、用这种方法随机生成方案。之后将方案的截图导出到CLIP模型中,转换成语义向量。3、另一方面,人为手动输入文本信息,例如:“我想要扎哈风格的酒店”,这个文本信息也被CLIP转换成语义向量。4、两个语义向量通过处理进行对比。得到差值。5、用遗传算法优化,迭代使得这个分割差值最少,从而完成设计。那么经过遗传算法迭代,最终人们就会得到屏幕截图与扎哈风格接近的3D模型。在郑豪教授最近发表的一些研究中,就经典采用了此种框架。

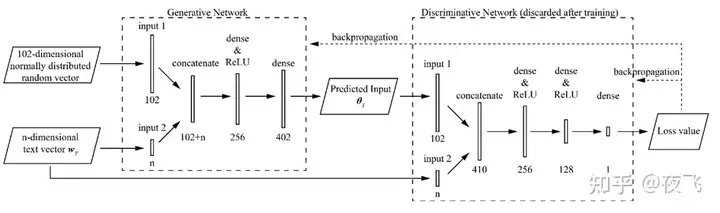
也有其它不借助于CLIP但仍然是基于text 输入形式生成的研究。这种情况基本需要人工打标签来完成模型的预训练。例如,在佛罗里达大学的一项研究中,研究人员首先用他们事先有的一种CEM方法随机生成了400个模型来构成数据集,然后通过人工标注建立了词嵌入向量和建筑形态之间的关系。之后,研究人员建立了对抗生成网络,可以通过输入的文本预测建筑形态。该研究具有极高的完成度,尤其是对抗生成网络的搭建,具有极高的参考意义。在最终的生成模型中,摆脱了既有的rule-based的结构生成算法,没有走遗传算法优化的路。
未来——Video, Code, Audio…and 3D!!!
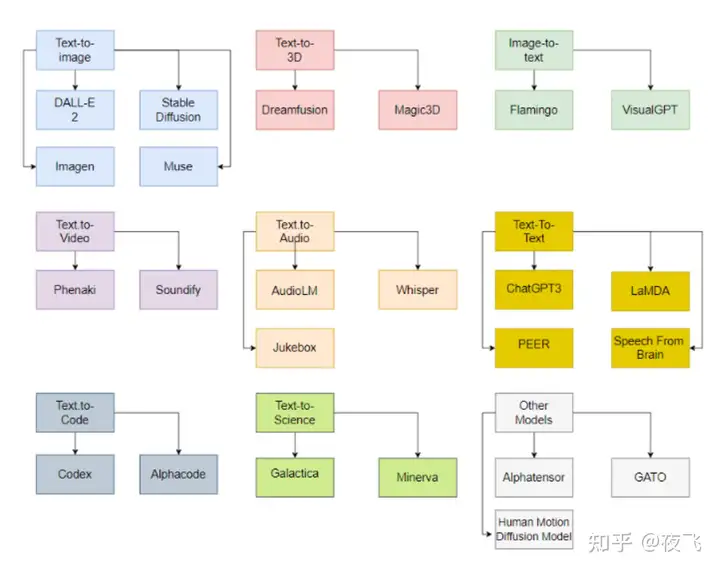
如果我们将视野放的更广,在过去五年,Generative AI 生成式AI已经有了长足的发展。除了文本到文本的ChatGPT、文本到图像外,还有图像到3D的平台(Kaedim, LucidPix…),文本到视频,文本到音频,文本到编码等等等等。值得一提的是,
在最近的几周,图像到3D正在取得飞速的进步,如谷歌发布的dreamFussion,英伟达发布的Magic3D等等,还有已存在很久的图像深度等研究。
然而,目前的三维模型生成器侧重于物体的视觉表现,通常表现形式为点云、网格、体素等,这与与建筑基于向量的离散3D模型有一些根本不同。由于篇幅问题,在此无法展开。以后会单独开新篇来详细解读。

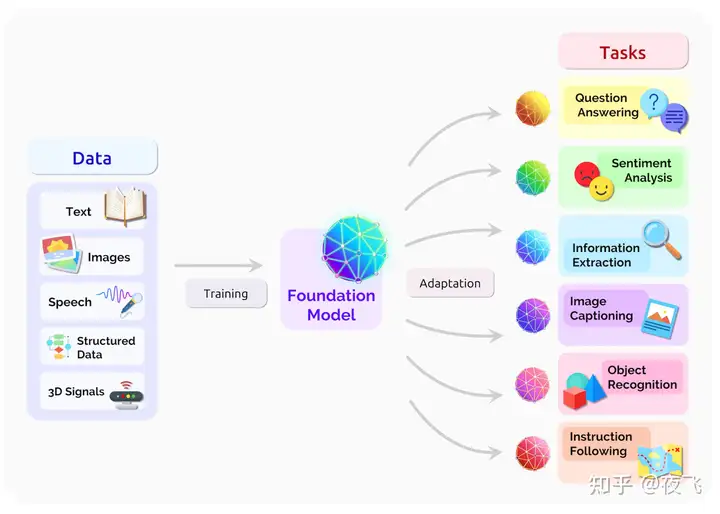
在2021年,面对GPT-3、CLIP的问世,在一篇 200 多页的论文中,Percy Liang、李飞飞等斯坦福研究者系统阐述了大规模预训练模型背后的机遇与风险。他们还给这些模型取了一个统一的名字—— Foundation Model。
在理想状态下,世间所有类型的数据,从文本到图像到视频、音频、3D都被作为训练集输入到模型训练之中。而训练好的巨型规模的神经网络模型将会被应用于解决任何问题,无论是翻译、识别、还是搜索、分析、还是模拟、预测,亦或者是生成、创造。大模型的强大能力来自其巨大的参数空间的结合,然而这也导致它们的可解释性非常差,存在系统性风险。
可能在一年前我们还认为这是痴人说梦,但是今年我们逐渐意识到,Moss离我们其实很近。
由于篇幅所限,本文涉及到知识范围和深度有限。此系列文章还会继续更新下去。
最后,欢迎关注公众 AAE建筑自编码研究组。
我们是一群主要来自于美国的AI设计博士,我们在AI,数字设计和建筑学的边界,致力于探究三维空间设计的自动化技术与创意。
“未来已来,只是还未平均分布”
#MidJourney #ChatGPT #GenerativeDesign #GenerativeAI



