
最近ChatGPT和New Bing火热,尤其是后者。当ChatGPT刚公开时,有人预测其会改变大家获取信息的方式,对搜索引擎会有很大影响,当时大家还不着急,认为ChatGPT具有会瞎编、说话没依据、没有实时性等致命缺陷,没想到微软紧锣密鼓就更新迭代ChatGPT,并整合成New Bing,既保留了ChatGPT的多轮对话能力,又保证生成的回答有据可依,且具有实时性。感慨技术发展之快,整理OpenAI GPT系列工作关键信息,供交流讨论。
“通用语言知识理解能力”
Open AI从2018年开始致力于Decoder形式的Large Language Model(LLM)的研究,ChatGPT能引起这么大的轰动,基础LLM模型的通用语言知识理解能力是关键,因此本文先介绍GPT 1-3系列的关键内容,包括规模、数据、核心贡献等。
GPT-1(2018)(Improving Language Understanding by Generative Pre-Training )
采用transformer decoder做语言模型,预训练阶段采用无监督数据, 损失函数用语言生成概率损失;预训练数据集采用BookCorpus, 里面有7000本未发表书(8亿词),涉及冒险、幻想、恋爱题材。12层transformer, 768 hidden size;微调阶段引入一个线性输出层(右图橙色部分)做下游任务,引入起始符、分隔符、结束符(右图蓝色部分)来构建不同下游任务的输入形式,微调阶段采用有监督数据,损失函数结合任务相关的损失以及语言生成概率损失;
GPT-2 (2019)(Language Models are Unsupervised Multitask Learners )
采用和GPT-1相似的结构 (部分改动包括初始化策略、pre-normalization等),最大版本48层,1600 hidden size,1.5B参数量构建一个更大预训练数据集WebText,其基于Reddit筛选45million的网页,然后抽取文本内容,最后得到8million的document,总共40GB,19B token数量;突出强调预语言模型zero-shot的能力,不finetune,直接测试多种生成式下游任务 (文本生成、阅读理解、问答、摘要、翻译),baseline模型也是当时的zero-shot SOTA;由于不finetune,就不能再像GPT-1中引入特殊符号构建下游任务输入的方式了,因此通过采用自然语言构建输入形式(后续论文称为prompt,这种方式可以追溯到salesforce 2018年一篇关于多任务的论文The natural language decathlon: Multitask learning as question answering)GPT-3 (2020) (Language Models are Few-Shot Learners)
GPT-1提出先无监督训练,再进行小数据量有监督训练,达到当时的SOTA;GPT-2为了突出创新型,强调无监督,但是效果相比有监督还是有差距;GPT-3则做了一下平衡,下游任务用监督数据,但是很少,使得数据成本很低,但是又保证效果,即few-shot;已有大模型在做下游各个任务时都需要微调参数,这 1)需要下游任务的数据标注,2)大模型在小数据上微调后表现更好不能证明大模型泛化性更好,很有可能是过拟合,3)人类不需要大量监督数据来做各种语言任务,因此不调参数直接能进行下游各种任务的执行是更理想的能力。GPT-3借鉴meta-learning, 认为大模型以及具备了各种解决复杂任务的基础能力,在下游任务时应该是激发各种能力,因此提出in-context learning,即做某种任务时,通过输入一些任务的样例(demonstration即演示)(测试的时候有三种情况:few-shot: 10-100个样例;one-shot:1个样例;zero-shot: 无样例),激发模型做这种特殊任务的能力,整个过程就是一个inference的过程,没有参数更新。模型结构类似GPT-2 (但采用了sparse transformer的结构) ,参数量是GPT-2的100倍,96层,12288 hidden size, 175B参数量;由于需要构建更大量的数据集,采用亚马逊的Common Crawl上爬取的网页,做一些处理进行数据清洗与过滤:1)使用GPT2的WebText数据作为正样本,Commone Crawl是原始数据作为负样本训练一个分类器,然后再处理一遍Common Crawl的数据,过滤太负面的数据;2)采用信息检索中的LSH算法进行文档去重,最终得到410B(4千亿)token数量的数据集训练时会同时用到其他数据集,包括WebText2 (19B tokens)、Books1 (12B tokens)、Books2 (55B tokens)、Wikipedia (3B tokens),总计是499B,数据量大概是GPT-2的20倍;训练时,对Commone Crawl这部分脏数据数据采样率没有很高,为60%,其他数据采样率之和为40%,各数据集采样率为60:22:8:8:3;GPT-3在一些任务上的性能已经十分接近finetune的效果;
“各类衍生能力研究”
到GPT3,LLM还仅仅是个语言模型,不具备代码书写、交流等能力,尽管有,也是微弱的体现,但这之后,Open AI开始对于GPT3各方面能力的增强,最后促成了ChatGPT。微软2018年收购github,2019年开始投资Open AI,2020年Open AI完成GPT 3之后,在2021年探索代码理解与生成,推出Codex;探索模型模拟人类进行信息检索,推出WebGPT,于2022年推出InstructGPT以及ChatGPT,于2023年整合New Bing,这些工作没有特别新颖的地方,算法实现几乎一样,但是回过头看,震惊的是上层领导者整体关于LLM落地的布局。
Codex(2021)(github提供的辅助代码编写服务copilot的算法原型)
该模型的功能是输入代码注释,自动生成python代码,训练方法和GPT完全一致;人工构建了一个新的代码生成评测集HumanEval,包含164个编程问题,每个问题有多个单元测试;评测采用pass@k, 计算思路大概就是生成n个代码,从其中sample k个,k个中至少1个能通过测试的概率。从github上爬取了2020年5月份之前的5千万个项目的python文件,过滤之后,大小有159G,作为第一阶段训练集;github上的数据集和评测数据集还是有domain gap,为此又额外从编程比赛中收集1万个问题答案以及github持续集成服务的中4万个左右问题和代码,这部分数据集作为第二阶段的训练希望语言模型能模拟人类使用浏览器得到问题答案的行为,对于一个问题,使用bing检索网上的内容,finetune的GPT3根据返回的内容,生成下一步动作(比如上滑下滑、点击某个页面、引用部分文本、停止搜索并回答等),当预测的动作为“停止搜索并回答”时,会对历史做summary。训练阶段包括三部分:让标注人员提供回答问题的演示,包括每一步动作和最后的答案。用这些数据对GPT3(175B)进行监督式微调,收集阶段一模型的回答,人为比较,收集的数据用于训练一个reward模型(第一阶段的模型移除最后预测层)通过第二阶段的reward模型,采用PPO对第一阶段的模型进行强化学习的微调应用时采用Rejection sampling策略,即让第一阶段和第三阶段的模型sample一些答案,让reward模型进行排序。【注】WebGPT的功能和New Bing目前具有的引用和实时性功能高度相似,但是New Bing到底有没有自主实现多步信息检索的能力存疑。因为目前看网上的演示,没有自主检索的证据,即使有,对用户也是隐藏的,仅凭具有引用的summary结果来看,ChatGPT也有可能做到,比如通过summary类型的pompt,然后加一些规则性的匹配来获得引用什么的。和一个检索领域的博士交流,他认为还没有,有的话,微软肯定会多吹一波自主检索能力的,哈哈。
InstructGPT(2022) (ChatGPT算法原型)
希望语言模型生成的回复更贴合用户的意向训练阶段和WebGPT一样分为三部分:收集人工标注的问题和答案,用于监督式微调GPT3(一部分问题来自于标注人员,一部分问题来自于网上用户)收集阶段一模型的多个回答,由标注人员进行排序,训练reward模型使用reward模型对阶段一的模型进行强化学习的微调
ChatGPT (2022)
根据官网描述,ChatGPT采用InstructGPT算法原型,构建对话类型的数据集,在GPT 3.5系列模型上进行finetune,参考网上资料,其技术路线可能如下:
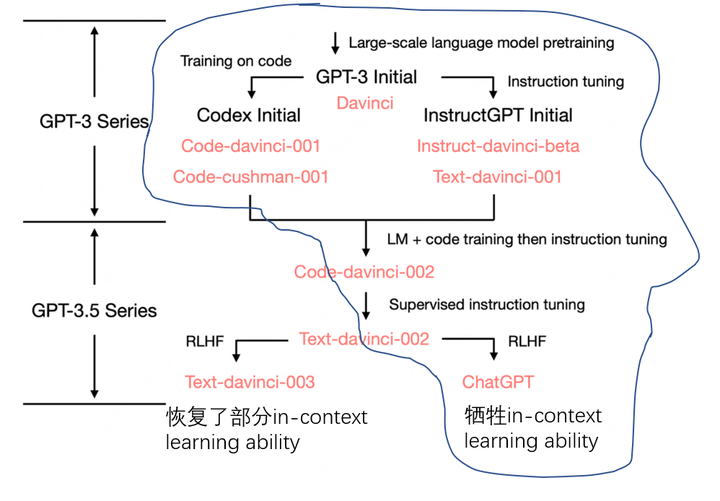
Open AI自2020年发布GPT3以来,这两年工作看起来都是GPT-3的衍生,增强各项能力,涉及大量数据工程,但这些感觉都还是小菜,即将到来的GPT-4应该才是重磅炸弹。



