
2022年12月份的时候,ChatGPT还只是个被人各种撩的聊天工具。但进入2023年后,已经向着效率工具迈进了。
微软宣布正和ChatGPT开发团队OpenAI进行洽谈,投资百亿美元,并计划把这个工具整合到云服务、搜索引擎、甚至office中。海外高校、学术机构,也兴起了关于用ChatGPT写论文是否合规的大讨论;咨询公司也开始担忧是否会被抢饭碗。
毫无疑问,ChatGPT的应用热情,已经被点燃;应用场景也不断拓展。但ChatGPT并不是一蹴而就,以更广阔的的视野来看,这背后是AIGC“智慧涌现”的大浪潮。那么,AIGC的发展节点有哪些?企业竞争靠什么?
AIGC是如何一步步突破的?
AI懂创作、会画画,可以说是人工智能的一个“跨越式”提升。虽然人工智能在生活中不断普及,比如我们习惯了机器代替人去搬运重物、制造精密的产品、完成复杂的计算等等。但是,如果人工智能更接近人,那就必须具备人类“创作”的能力。这就是AIGC的意义。
AI能力的提升,并不是一蹴而就,而大部分则经历了“模型突破-大幅提升-规模化生产-遇到障碍-再模型突破-大幅提升”的循环发展。而要实现落地、走进人类生活,则必须具备“规模化生产”的能力,在资源消耗、学习门槛等方面大幅降低到平民化。
比如以AI画画为例,则经历了三个关键节点:
第一个节点,早期突破:2014年,对抗生成网络(GAN)诞生,真正“教会”AI自己画画。
GAN包含两个模型,一个是生成网络G、一个是判别网络D。G负责把接收到的随机噪声生成图片,D则要判断这张图是G画的、还是现实世界就存在的。G、D互相博弈,能力也不断提升,而当D不再能判断出G生成的图片时,训练就达到了平衡。
GAN的开创性在于,精巧地设计了一种“自监督学习”方式,跳出了以往监督学习需要大量标签数据的应用困境,可以广泛应用于图像生成、风格迁移、AI艺术和黑白老照片上色修复。
但其缺陷也正来源于这一开创性:由于需要同步训练两个模型,GAN的稳定性较差,容易出现模式崩溃。以及另一个有趣的现象“海奥维提卡现象”(the helvetica scenario):如果G模型发现了一个能够骗过D模型的bug,它就会开始偷懒,一直用这张图片来欺骗D,导致整个平衡的无效。
模型也会躺平,这鸡贼的特性,真是有人的风格。
第二个节点,大幅提升:2020年,一篇关于扩散模型(Diffusion Model)的学术论文,大幅提升AI的画画水平。
扩散模型的原理是“先增噪后降噪”。首先给现有的图像逐步施加高斯噪声,直到图像被完全破坏,然后再根据给定的高斯噪声,逆向逐步还原出原图。当模型训练完成后,输入一个随机的高斯噪声,便能“无中生有”出一张图像了。
这样的设计大大降低了模型训练难度,突破了GAN模型的局限,在逼真的基础上兼具多样性,也就能够更快、更稳定的生成图片。
扩散模型在AI业界的“起飞”源于2021年1月,Open AI基于此开发出DALL·E文字生成图片模型,能够生成接近真实生活但并不真实存在的图片,让AI业界震了三震。但由于在像素空间进行了大量计算,这一模型仍存在进程缓慢、内存消耗大的缺陷。
第三个节点,批量生产:2022年夏天诞生的Stable Diffusion,让高大上的学术理论变得“接地气”。
去年8月,Stability AI将扩散过程放到更低维度的潜空间(Latent Diffusion),从而开发出了Stable Diffusion模型。这个模型带来的提升,在于资源消耗大幅降低,消费级显卡就可以驱动的,可以操作也更为方便,普通人也可以体会到人工智能惊艳的创作能力。而且开发团队还把所有代码、模型和权重参数库都进行了开源,践行了Geek的共享精神、去中心化主义。
门槛降低、效果提升,因此,大受欢迎。发布10天后,活跃数据达到了每天1700万张,如果都用A4纸打印出来叠一起,相当于一座52层高的大楼。
共享,也是Stability AI的另一特色。在开源社区中,除了更小的内存和更快的速度,Stable Diffusion收获了更完善的指南与教程、共享提示词、新UI,也依靠集体的智慧,走进了Photoshop、Figma等经典软件,汇入创作者们的既有工作流中。可谓是,依靠群众、回馈群众。
从技术实现突破、到技术提升、再到规模化降低门槛,AI创作能力也不断提升。2022年10月,美国一名男子用AI绘画工具Midjourney,生成了一幅名为《太空歌剧院》的作品,并获得了第一名。这引起了一波不小的争论,也终于形成了一条新赛道。于是,2022年以AI绘画为代表的各种生成式AI工具,如雨后春笋般疯狂冒尖,比如盗梦师、意间AI、6pen、novelAI等等。
而在文本AI领域也是如此。如今大火的ChatGPT则是基于GPT3.5模型,已经迭代了4次。而对话一次的平均成本为0.01-0.2美元,也就是六毛到一块钱人民币,成本依然需要不断降低。但整体而言,无论画画、还是聊天,AI已经体现出智慧涌现。
如何成为浪潮宠儿?
Stability AI的创始人Emad认为,图像才是杀手级应用。
图像模型可以迅速创造,并引导人们迅速消费,同时又能以较低成本快速整合到不同领域,从而快速普及,掀起浪潮。而事实上,确实许多创业者涌入了这些领域。AIGC成为了币圈之后的投资新焦点。在 GPT-3 发布的两年内,风投资本对 AIGC 的投资增长了四倍,在 2022 年更是达到了 21 亿美元。
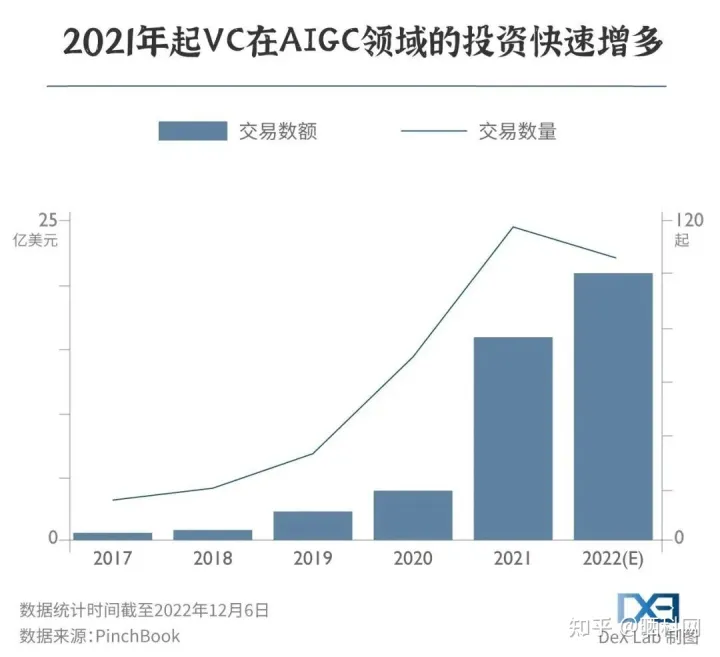
公司增多,投资增多,但并不是每家企业都能活得很好。比如2022年底,仅创立4个月的AI绘画公司StockAI就停止了运营。公司CEO表示,主要是因为商业化模式不成熟,目前的付费用户群体无法覆盖高昂的运营成本。虽然他也表明会在今年1月份推出全新的平台,但从透露的信息来看,新平台已不会有需要大量算力的AI图片生成功能了。
那么,什么样的企业,才是这波浪潮的“宠儿”?
首先,无疑是掌握核心前沿技术的行业引领者。全球TOP3的人工智能研究机构,都在各出奇招、争夺AIGC主导地位。
OpenAI是文字生成领域的领航员。不光吸引了“生成对抗网络之父”Ian Goodfellow加盟,还早早获得了微软的10亿美元投资。从GPT到GPT3.5,OpenAI不断迭代,也不断带给行业惊喜。这一次的ChatGPT更加获得了微软的认可。而通过开放GPT-3受控API的模式,OpenAI也将赋能更多公司和创业者。
DeepMind是通用型AI的探路人。2016年,AlphaGo击败人类围棋的最高代表韩国棋手李世石,Go背后正是谷歌旗下的DeepMind。但DeepMind的目标并不是下棋,而是通用型AI,比如能预测蛋白质结构的AlphaFold、能解决复杂数学计算的AlphaTensor等等。但这些AI始终面临着一个瓶颈,即无法像人类一样进行“无中生有”的创作。
这两年,DeepMind终于向通用型AI又推近了一步。在对话机器人Sparrow、剧本创作机器人Dramatron等背后的语言大模型中找到灵感,构建了会聊天、会干活、会玩游戏的Gato。
Meta在加速AI的商业化落地。重组调整AI部门,将其分布式地下放到各实际业务中,而FAIR被并入元宇宙核心部门Reality Labs Research,成为新场景探索者的一员。
也许同行相轻,Meta首席人工智能科学家Yann LeCun对ChatGPT的评价并不高,他认为从底层技术上看,ChatGPT并不是什么创新性、革命性的发明,除了谷歌和Meta,至少有六家初创公司拥有类似的技术。
当被问及Meta的AI愿景时,LeCun为FAIR画下了“生成艺术”的大饼。他提出,Facebook上有1200万商铺在投放广告,其中多是没有什么资源定制广告的夫妻店,Meta将通过能够自动生成宣传资料的AI帮助他们做更好的推广。
其次,另一类宠儿,则是押对应用场景的企业们,在“绘画”之外吸纳了不少资本支持与人才投入。
在所有内容生成式AI中,输出文字和音乐的已经先一步找到了财富密码。最早出现的AI生成文字在遍历了写新闻稿、写诗、写小剧本等颇受关注的应用方式后,终于在营销场景找到了能够稳定变现的商业模式,成为写作辅助的效率工具,帮助从业者写邮件、文案、甚至策划。专注于音乐的LifeScore,则让人工智能学会了即时编曲,按照场景、长度的需要,组织艺术家同事人工创作、演奏的音乐素材,在人类的创作流程中找到了自己的位置。
能够互动的聊天机器人,则在客服和游戏这两个相去甚远的行业分别“打工”。区别于当下只会提供预设问题解答,有时还会答非所问的“智能客服”,真正的AI需要结合用户的行为和上下文来理解人类的真正意图。在游戏领域,AI则被用来协助人类,高效地创造内容丰富、体验良好的游戏内容,从而延长用户的游戏时间。
显然,宠儿是少的。而经历了过去一年多“科技股大回落”后,投资者们也谨慎一些了,当下的AIGC虽然很好,但等大模型出来也许更香。
大模型,也许是企业比拼的护城河
模型是人工智能的灵魂,本质上它是一套计算公式和数学模型。“参数”可以看做是模型里的一个个公式,这意味着,参数量越大,模型越复杂,做出来的预测就越准确。
小模型就像“偏科的机器”,只学习针对特定应用场景的有限数据,“举一反三”能力不足,一些智能产品被用户调侃为“人工智障”的情况时有发生。
大模型就是参数量极大的模型,目前业界主流的AIGC模型都是千亿级、万亿级参数量的水平。通过学习各行各业各类数据,除了能给出相较于小模型更准确的预测结果之外,它也展现出了惊人的泛化能力、迁移能力,产出内容质量更高、更智能,这也是当前AIGC工具让人眼前一亮的原因
而大模型的快速发展,对行业发展起到了明显的推动作用。例如ChatGPT是基于GPT-3模型进行优化所产生的,引领AI绘画发展的DALL·E 2也离不开GPT-3的贡献。类似的还有Deepmind的Chinchilla、百度的文心大模型等等。
大模型,很大概率是行业淘汰与否的判断要素。
首先,训练数据量大,OpenAI为了让GPT-3的表现更接近人类,用了45TB的数据量、近 1 万亿个单词来训练它,大概是1351万本牛津词典
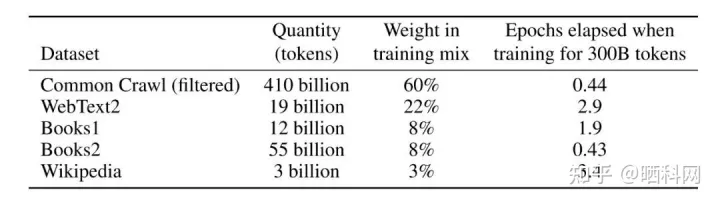
这就带来了两个问题:巨大的算力需求与资金消耗。训练和运行模型都需要庞大的算力,有研究估测,训练 1750 亿参数语言大模型 GPT-3,需要有上万个 CPU/GPU 24 小时不间输入数据,所需能耗相当于开车往返地球和月球,且一次运算就要花费450万美元。
国内也不例外。目前国内自研的大模型包括百度的文心大模型、阿里的M6大模型、腾讯的混元大模型,针对中文语境,国内厂商的表现要比国外大厂要好得多。而且国内的大模型发展速度也很惊人。
采用稀疏MoE结构的M6大模型,2021年3月仅1000亿参数,3个月后就达到了万亿级,又过了五个月模型参数达到了十万亿级,成为全球最大的AI预训练模型。混元模型也是万亿级别,成本大幅降低,最快用256张卡,1天内就能训练完成。而采用稠密结构(可以粗糙理解是和稀疏相比,密度更大)的文心大模型,2021年,参数规模达到2600亿。2022年,百度又先后发布了数十个大模型,其中有11个行业大模型。
这样高的研发门槛,注定目前主流的大模型多由大企业、或是背靠大企业的研究机构掌握,中小企业只能望而却步。因此,大模型,也就成为企业的“护城河”。
但进行大模型的研发只是“成功第一步”,还有三个维度的比拼,也非常重要。
一是数据资源。有研究表明,到2026年就没有更多高质量的数据可以训练AI了。此外,基于现实生活中已有的数据来训练模型只能解决一些已知问题,对于一些我们还没有发现的、潜在的、未知的问题,现在的模型未必能解决。因此有一些研究人员提出了合成数据的概念,即通过计算机程序人工合成的数据,一方面补充高质量的训练数据,另一方面填补一些极端或者边缘的案例,增加模型的可靠性。
二是绿色发展。虽然模型越大效果越好,但无限“大”下去并不经济,对自然资源消耗、数据资源都带来巨大压力。而过高的资源消耗,也不利于平民化普及。
三是应用场景。商业和纯理论研究不同,不能拿着技术的锤子,瞎找钉子,而是要结合应用来发展技术。而国内厂商要想拿出Stable Diffusion、ChatGPT这样的杀手级应用,还需要更多的思考和努力:
跳出“跑分”怪圈,找到应用场景,进行模型“瘦身”,甚至,将模型开源、形成生态,利用群众的智慧、为群众服务。
尾声
随着微软对ChatGPT的关注,产业、投资圈都热了起来,美股BuzzFeed因为要采用ChatGPT技术就实现了两天涨三倍的壮举;H股、A股也迎风而动,不少上市公司也表态具备技术积累。
躁动当然是好事儿,科技创新,就是要令人心潮澎湃。我国广阔的产业,是应用开花的土壤。但与此同时,国内的AIGC也存在着隐忧,比如高算力的芯片,如何造出来?
另一方面,科技创新,也要牢记Gartner曲线揭示的规律:萌发期→泡沫期→泡沫破裂期→稳步发展期→稳定产出期。只有躁动,没有笃定、没有低谷时的忍耐,也绝不可能成功的。
适度的泡沫,成为驱动力;过度的泡沫,也许会劣币驱逐良币。但至少目前,我们和海外相比,几乎在同一起跑线,值得充满热情的期待。
来源:远川科技评论
链接:晒科网



